ClickStack - Оптимизация производительности
Введение
В этом руководстве рассматриваются наиболее распространённые и эффективные оптимизации производительности для ClickStack, достаточные для оптимизации большинства реальных нагрузок обсервабилити, обычно до десятков терабайт данных в день.
Оптимизации представлены в продуманном порядке: начиная с самых простых и дающих наибольший эффект техник и переходя к более продвинутой и специализированной настройке. Ранние оптимизации следует применять в первую очередь — часто они сами по себе дают существенный прирост производительности. По мере роста объёмов данных и усложнения нагрузок более поздние техники становятся всё более актуальными для изучения и применения.
Концепции ClickHouse
Прежде чем применять какие-либо из оптимизаций, описанных в этом руководстве, важно ознакомиться с несколькими ключевыми концепциями ClickHouse.
В ClickStack каждый источник данных напрямую сопоставляется с одной или несколькими таблицами ClickHouse. При использовании OpenTelemetry ClickStack создаёт и управляет набором таблиц по умолчанию, которые хранят логи, трейсы и метрики. Если вы используете собственные схемы или управляете своими таблицами, вы, вероятно, уже знакомы с этими концепциями. Однако, если вы просто отправляете данные через OpenTelemetry Collector, эти таблицы создаются автоматически, и именно к ним будут применены все описанные ниже оптимизации.
| Тип данных | Таблица |
|---|---|
| Logs | otel_logs |
| Traces | otel_traces |
| Metrics (guages) | otel_metrics_gauge |
| Metrics (sums) | otel_metrics_sum |
| Metrics (histogram) | otel_metrics_histogram |
| Metrics (Exponential histograms) | otel_metrics_exponentialhistogram |
| Metrics (summary) | otel_metrics_summary |
| Sessions | hyperdx_sessions |
Таблицы относятся к базам данных в ClickHouse. По умолчанию используется база данных default — это можно изменить в коллекторе OpenTelemetry.
В большинстве случаев настройка производительности сосредоточена на таблицах логов и трейсов. Хотя таблицы метрик можно оптимизировать под фильтрацию, их схемы преднамеренно ориентированы на рабочие нагрузки в стиле Prometheus и обычно не требуют модификации для стандартной визуализации. Логи и трейсы, напротив, поддерживают более широкий спектр паттернов доступа и поэтому сильнее всего выигрывают от настройки. Данные сессий имеют фиксированный пользовательский интерфейс, и их схема редко нуждается в изменении.
Как минимум, вам следует понимать следующие основы ClickHouse:
| Концепция | Описание |
|---|---|
| Таблицы | Как источники данных в ClickStack соответствуют базовым таблицам ClickHouse. Таблицы в ClickHouse в основном используют движок MergeTree. |
| Части | Как данные записываются в неизменяемые части и со временем сливаются. |
| Партиции | Партиции группируют части таблицы в организованные логические единицы. Этими единицами проще управлять, их проще запрашивать и оптимизировать. |
| Слияния | Внутренний процесс, который объединяет части, чтобы уменьшить их количество для запроса. Критически важен для поддержания производительности запросов. |
| Гранулы | Наименьшая единица данных, которую ClickHouse читает и отсеивает во время выполнения запроса. |
| Первичные (упорядочивающие) ключи | Как ключ ORDER BY определяет расположение данных на диске, сжатие и отсечение данных при выполнении запросов. |
Эти концепции являются ключевыми для производительности ClickHouse. Они определяют, как данные записываются, как они структурированы на диске и насколько эффективно ClickHouse может пропускать чтение данных во время выполнения запроса. Каждая оптимизация в этом руководстве — будь то материализованные столбцы, пропускающие индексы, первичные ключи, проекции или materialized view — опирается на эти базовые механизмы.
Рекомендуется ознакомиться со следующей документацией ClickHouse перед началом настройки:
- Создание таблиц в ClickHouse — простое введение в таблицы.
- Части
- Партиции
- Слияния
- Первичные ключи/индексы
- Как ClickHouse хранит данные: части и гранулы — более продвинутое руководство о том, как данные структурированы и запрашиваются в ClickHouse, с подробным разбором гранул и первичных ключей.
- MergeTree — продвинутое справочное руководство по MergeTree, полезное для команд и понимания внутренних деталей.
Все описанные ниже оптимизации могут быть непосредственно применены к исходным таблицам с использованием стандартного ClickHouse SQL, либо через консоль ClickHouse Cloud SQL, либо через клиент ClickHouse.
Оптимизация 1. Материализация часто запрашиваемых атрибутов
Первая и самая простая оптимизация для пользователей ClickStack — определить часто запрашиваемые атрибуты в LogAttributes, ScopeAttributes и ResourceAttributes и вынести их на верхний уровень в виде отдельных материализованных столбцов.
Одна только эта оптимизация часто бывает достаточна, чтобы масштабировать развертывания ClickStack до десятков терабайт в день, и её следует применять прежде, чем переходить к более продвинутым методам настройки.
Зачем материализовывать атрибуты
ClickStack хранит метаданные, такие как метки Kubernetes, метаданные сервисов и пользовательские атрибуты, в столбцах типа Map(String, String). Хотя это обеспечивает гибкость, выполнение запросов к отдельным ключам внутри map-столбца имеет важные последствия для производительности.
При выборке одного ключа из столбца типа Map ClickHouse должен прочитать весь столбец с диска. Если map содержит много ключей, это приводит к лишним операциям ввода-вывода и более медленным запросам по сравнению с чтением отдельного столбца.
Материализация часто запрашиваемых атрибутов позволяет избежать этих накладных расходов за счёт извлечения значения во время вставки и сохранения его как полноценного столбца.
Материализованные столбцы:
- Вычисляются автоматически при вставке данных
- Не могут быть явно заданы в командах INSERT
- Поддерживают любые выражения ClickHouse
- Позволяют конвертировать тип из String в более эффективные числовые или временные типы
- Позволяют использовать пропускающие индексы и первичный ключ
- Снижают объём чтения с диска, избегая полного доступа к map
ClickStack автоматически обнаруживает материализованные столбцы, извлечённые из map, и прозрачно использует их при выполнении запросов, даже если пользователи продолжают запрашивать исходный путь к атрибуту.
Пример
Рассмотрим используемую по умолчанию схему ClickStack для трассировок, где метаданные Kubernetes хранятся в ResourceAttributes:
Пользователь может фильтровать трейсы с помощью синтаксиса Lucene, например ResourceAttributes.k8s.pod.name:"checkout-675775c4cc-f2p9c":
Это приводит к SQL-предикату вида:
Поскольку при обращении по ключу в Map ClickHouse должен прочитать весь столбец ResourceAttributes для каждой подходящей строки, он может оказаться очень большим, если в Map содержится много ключей.
Если к этому атрибуту часто обращаются в запросах, его следует материализовать как столбец верхнего уровня.
Чтобы извлечь имя пода во время вставки данных, добавьте материализованный столбец:
Начиная с этого момента, новые данные будут сохранять имя пода в отдельном столбце PodName.
Теперь пользователи могут эффективно выполнять запросы по именам подов, используя синтаксис Lucene, например PodName:"checkout-675775c4cc-f2p9c".
Для вновь вставляемых данных это полностью устраняет обращения к map и существенно снижает объём операций ввода-вывода.
Однако даже если пользователи продолжают выполнять запросы, используя исходный путь атрибута, например ResourceAttributes.k8s.pod.name:"checkout-675775c4cc-f2p9c", ClickStack автоматически перепишет этот запрос внутренне так, чтобы использовать материализованный столбец PodName, то есть предикат вида:
Это гарантирует, что пользователи получают преимущества от оптимизации без изменения дашбордов, оповещений или сохранённых запросов.
По умолчанию материализованные столбцы исключаются из запросов SELECT *. Это сохраняет инвариант, что результаты запросов всегда можно повторно вставить в таблицу.
Материализация исторических данных
Материализованные столбцы автоматически применяются только к данным, вставленным после создания столбца. Для уже существующих данных запросы к материализованному столбцу будут прозрачно выполняться, читая данные из исходной карты (map).
Если производительность для исторических данных критична, столбец можно ретроспективно заполнить с помощью мутации, например
Эта операция перезаписывает существующие parts, чтобы заполнить столбец. Мутации выполняются в одном потоке для каждой части и могут занимать много времени на больших наборах данных. Чтобы снизить влияние, область действия мутаций можно ограничить конкретной партицией:
Ход выполнения мутаций можно отслеживать с помощью таблицы system.mutations, например:
Дождитесь, пока для соответствующей мутации is_done = 1.
Мутации создают дополнительную нагрузку на IO и CPU и должны использоваться экономно. Во многих случаях достаточно дать старым данным естественным образом устареть и полагаться на повышение производительности для вновь поступающих данных.
Оптимизация 2. Добавление индексов пропуска данных
После материализации часто запрашиваемых атрибутов следующим шагом оптимизации является добавление индексов пропуска данных, чтобы ещё больше сократить объём данных, который ClickHouse должен прочитать во время выполнения запроса.
Индексы пропуска данных позволяют ClickHouse избегать сканирования целых блоков данных, когда можно определить, что подходящих значений не существует. В отличие от традиционных вторичных индексов, индексы пропуска данных работают на уровне гранул и наиболее эффективны, когда фильтры запроса исключают большие части набора данных. При корректном использовании они могут значительно ускорить фильтрацию по атрибутам с высокой кардинальностью без изменения семантики запроса.
Рассмотрим схему трасс по умолчанию для ClickStack, которая включает индексы пропуска данных:
Эти индексы ориентированы на два распространённых сценария:
- Фильтрация строк с высокой кардинальностью, таких как TraceId, идентификаторы сессий, ключи атрибутов или значения
- Фильтрация по числовым диапазонам, например по длительности спанов
Фильтры Блума
Индексы с фильтрами Блума являются наиболее часто используемым типом пропускающих индексов в ClickStack. Они хорошо подходят для строковых столбцов с высокой кардинальностью — как правило, по крайней мере десятки тысяч различных значений. Вероятность ложноположительного срабатывания 0.01 при гранулярности 1 — это хороший вариант по умолчанию, обеспечивающий баланс между накладными расходами на хранение и эффективностью отсечения.
Продолжая пример из Оптимизации 1, предположим, что имя пода Kubernetes было материализовано из ResourceAttributes:
Чтобы ускорить фильтрацию по этому столбцу, можно добавить пропускающий индекс Bloom-фильтра:
После добавления skip index его необходимо материализовать — см. "Materialize skip index."
После создания и материализации ClickHouse может пропускать целые гранулы, в которых гарантированно не содержится запрошенное имя пода, что потенциально уменьшает объём данных, читаемых при выполнении запросов, таких как PodName:"checkout-675775c4cc-f2p9c".
Фильтры Блума наиболее эффективны, когда распределение значений таково, что конкретное значение встречается в относительно небольшом количестве частей. Это часто естественным образом происходит в нагрузках обсервабилити, где метаданные, такие как имена подов, trace ID или идентификаторы сессий, коррелируют со временем и, следовательно, кластеризованы по ключу сортировки таблицы.
Как и все skip index, фильтры Блума следует добавлять избирательно и проверять на реальных шаблонах запросов, чтобы убедиться, что они дают измеримую пользу — см. "Evaluating skip index effectiveness."
Индексы min-max
Индексы min-max сохраняют минимальное и максимальное значение по каждому гранулу и являются крайне легковесными. Они особенно эффективны для числовых столбцов и диапазонных запросов. Хотя они ускоряют далеко не каждый запрос, их стоимость низка, и их почти всегда имеет смысл добавлять для числовых полей.
Индексы min-max лучше всего работают, когда числовые значения либо естественным образом упорядочены, либо ограничены узкими диапазонами внутри каждой части.
Предположим, смещение в Kafka часто запрашивается из SpanAttributes:
Это значение можно материализовать и привести к числовому типу:
Теперь можно добавить индекс minmax:
Это позволяет ClickHouse эффективно пропускать части при фильтрации по диапазонам смещений Kafka, например при отладке лага потребителя или поведения при повторном воспроизведении.
Как и прежде, индекс должен быть материализован до того, как им можно будет воспользоваться.
Материализовать skip-индекс
После того как skip-индекс был добавлен, он применяется только к вновь поступающим данным. Исторические данные не смогут воспользоваться преимуществами индекса, пока он не будет явно материализован.
Если вы уже добавили skip-индекс, например:
Необходимо явно построить индекс для уже имеющихся данных:
Материализация skip-индекса, как правило, легковесна и безопасна для выполнения, особенно для индексов minmax. Для индексов Bloom filter на больших наборах данных пользователи могут предпочесть материализовывать их по партициям, чтобы лучше контролировать использование ресурсов, например:
Материализация skip-индекса выполняется как мутация. За ходом её выполнения можно отслеживать с помощью системных таблиц.
Дождитесь, пока для соответствующей мутации значение is_done не станет равным 1.
После завершения убедитесь, что данные индекса были созданы:
Ненулевые значения указывают на то, что индекс был успешно материализован.
Важно понимать, что размер индекса пропуска данных напрямую влияет на производительность запросов. Очень большие индексы пропуска данных, порядка десятков или сотен гигабайт, могут заметно дольше вычисляться во время выполнения запроса, что может снизить или даже свести на нет их пользу.
На практике индексы minmax обычно очень маленькие и требуют мало ресурсов при вычислении, поэтому их почти всегда безопасно материализовывать. Индексы на основе фильтра Блума, напротив, могут значительно расти в зависимости от кардинальности, гранулярности и вероятности ложных срабатываний.
Размер фильтра Блума можно уменьшить, повысив допустимую долю ложноположительных результатов. Например, увеличение параметра вероятности с 0.01 до 0.05 приводит к более компактному индексу, который вычисляется быстрее, ценой менее агрессивного отсечения. Хотя будет пропущено меньше гранул, общая задержка выполнения запроса может уменьшиться за счет более быстрого вычисления индекса.
Настройка параметров фильтра Блума, таким образом, является оптимизацией, зависящей от рабочей нагрузки, и должна проверяться с использованием реальных паттернов запросов и объемов данных, максимально приближенных к боевым.
Для более подробной информации об индексах пропуска данных см. руководство "Понимание индексов пропуска данных в ClickHouse"
Оценка эффективности индексов пропуска
Наиболее надёжный способ оценить отсечение с помощью индексов пропуска — использовать EXPLAIN indexes = 1, который показывает, сколько частей и гранул исключается на каждом этапе планирования запроса. В большинстве случаев желательно видеть значительное уменьшение числа гранул на этапе Skip, причём после того, как первичный ключ уже сократил пространство поиска. Индексы пропуска оцениваются после отсечения по партициям и первичному ключу, поэтому их влияние лучше всего измерять относительно оставшихся частей и гранул.
EXPLAIN подтверждает, происходит ли отсечение, но не гарантирует итоговое ускорение. Оценка индексов пропуска тоже стоит ресурсов, особенно если индекс большой. Всегда замеряйте производительность запросов до и после добавления и материализации индекса, чтобы подтвердить реальные улучшения.
Например, рассмотрим индекс пропуска Bloom filter по умолчанию для TraceId, включённый в стандартную схему Traces:
Вы можете использовать EXPLAIN indexes = 1, чтобы оценить, насколько эффективны индексы для селективного запроса:
В этом случае фильтр по первичному ключу сначала существенно сокращает набор данных (с 35898 гранул до 255), а затем фильтр Блума дополнительно сужает его до одной гранулы (1/255). Это идеальный сценарий для skip-индексов: отсечение по первичному ключу уменьшает область поиска, после чего skip-индекс отбрасывает большую часть оставшихся данных.
Чтобы оценить реальный эффект, измерьте производительность запроса при стабильных настройках и сравните время выполнения. Используйте FORMAT Null, чтобы избежать накладных расходов на сериализацию результата, и отключите кэш условий запроса, чтобы запуски были воспроизводимыми:
Теперь выполните тот же запрос с отключёнными skip-индексами:
Отключение use_query_condition_cache гарантирует, что результаты не зависят от кэшированных решений по фильтрации, а установка use_skip_indexes = 0 обеспечивает чистую отправную точку для сравнения. Если отсечение (pruning) эффективно и стоимость оценки индекса низкая, запрос с индексом должен быть заметно быстрее, как в примере выше.
Если EXPLAIN показывает минимальное отсечение гранул или skip-индекс очень большой, стоимость его оценки может свести на нет любую выгоду. Используйте EXPLAIN indexes = 1, чтобы подтвердить отсечение, затем проведите бенчмаркинг, чтобы подтвердить улучшение сквозной производительности.
Когда добавлять пропускающие индексы
Пропускающие индексы следует добавлять выборочно, исходя из типов фильтров, которые пользователи используют чаще всего, и структуры данных в частях и гранулах. Цель состоит в том, чтобы отбросить достаточно гранул, чтобы компенсировать стоимость вычисления самого индекса, поэтому тестирование на данных, близких к боевым, крайне важно.
Для числовых столбцов, которые используются в фильтрах, minmax-пропускающий индекс почти всегда является хорошим выбором. Он легковесный, дешевый в вычислении и может быть эффективен для диапазонных предикатов — особенно когда значения слабо упорядочены или ограничены узкими диапазонами внутри частей. Даже если minmax не помогает для какого‑то конкретного шаблона запроса, его накладные расходы обычно достаточно низки, чтобы его имело смысл оставить.
Строковые столбцы. Используйте фильтры Блума, когда кардинальность высокая, а значения разреженные.
Фильтры Блума наиболее эффективны для строковых столбцов с высокой кардинальностью, где каждое значение встречается относительно редко, то есть большинство частей и гранул не содержат искомого значения. В качестве ориентировочного правила фильтры Блума наиболее перспективны, когда столбец имеет как минимум 10 000 различных значений, а наилучшую производительность часто показывают при 100 000+ различных значений. Они также более эффективны, когда совпадающие значения сгруппированы в небольшом числе последовательных частей, что обычно происходит, когда столбец коррелирован с ключом сортировки. Однако результаты здесь могут различаться — ничто не заменит тестирование на реальных данных.
Optimization 3. Modifying the primary key
Первичный ключ — один из важнейших компонентов настройки производительности ClickHouse для большинства нагрузок. Чтобы эффективно его настраивать, необходимо понимать, как он работает и как он взаимодействует с вашими паттернами запросов. В конечном итоге первичный ключ должен соответствовать тому, как пользователи обращаются к данным, в частности, по каким столбцам фильтрация выполняется чаще всего.
Хотя первичный ключ также влияет на сжатие и физическое расположение данных, его основное назначение — производительность запросов. В ClickStack первичные ключи «из коробки» уже оптимизированы под наиболее распространённые паттерны доступа в задачах обсервабилити и под высокую степень сжатия. Ключи по умолчанию для таблиц логов, трейсов и метрик спроектированы так, чтобы хорошо работать для типичных сценариев.
Фильтрация по столбцам, которые идут раньше в первичном ключе, более эффективна, чем фильтрация по столбцам, которые идут позже. Хотя конфигурации по умолчанию достаточно для большинства пользователей, есть случаи, когда изменение первичного ключа может улучшить производительность для конкретных типов нагрузок.
В этом документе термины "ordering key" и "primary key" используются как взаимозаменяемые. Строго говоря, в ClickHouse они различаются, но для ClickStack они, как правило, означают одни и те же столбцы, указанные в ORDER BY таблицы. Подробности см. в документации ClickHouse о выборе первичного ключа, отличающегося от ключа сортировки.
Перед изменением любого первичного ключа настоятельно рекомендуется ознакомиться с нашим руководством по пониманию того, как работают первичные индексы в ClickHouse:
Настройка первичного ключа специфична для таблицы и типа данных. Изменение, полезное для одной таблицы и типа данных, может быть неприменимо к другим. Цель всегда — оптимизация под конкретный тип данных, например логи.
Обычно вы будете оптимизировать таблицы для логов и трейсов. Необходимость изменения первичного ключа для других типов данных возникает редко.
Ниже приведены первичные ключи по умолчанию для таблиц ClickStack для логов и метрик.
- Logs (
otel_logs) -(ServiceName, TimestampTime, Timestamp) - Traces ('otel_traces) -
(ServiceName, SpanName, toDateTime(Timestamp))
См. "Tables and schemas used by ClickStack" для первичных ключей, используемых в таблицах для других типов данных. Например, таблицы трейсов оптимизированы для фильтрации по имени сервиса и имени спана, затем по метке времени и идентификатору трейса. Таблицы логов, напротив, оптимизированы для фильтрации по имени сервиса, затем по дате и затем по метке времени. Хотя оптимальным было бы применение фильтров пользователем в порядке следования столбцов первичного ключа, запросы всё равно будут существенно выигрывать при фильтрации по любому из этих столбцов в любом порядке, поскольку ClickHouse будет отсекать данные перед чтением.
При выборе первичного ключа также есть и другие аспекты, связанные с выбором оптимального порядка столбцов. См. "Choosing a primary key."
Первичные ключи следует изменять изолированно для каждой таблицы. То, что разумно для логов, может быть неразумно для трейсов или метрик.
Выбор первичного ключа
Сначала определите, отличаются ли ваши шаблоны доступа к данным существенно от значений по умолчанию для конкретной таблицы. Например, если вы чаще всего фильтруете логи по Kubernetes-узлу, а уже потом по имени сервиса, и это представляет собой доминирующий рабочий процесс, это может оправдывать изменение первичного ключа.
Первичные ключи по умолчанию в большинстве случаев достаточны. Изменения следует вносить осторожно и только при четком понимании шаблонов запросов. Модификация первичного ключа может ухудшить производительность для других рабочих процессов, поэтому тестирование обязательно.
После того как вы выделили нужные вам столбцы, можно приступать к оптимизации ключа упорядочивания/первичного ключа.
Для выбора ключа упорядочивания можно применить несколько простых правил. Они иногда могут противоречить друг другу, поэтому учитывайте их по порядку. Стремитесь выбрать максимум 4–5 ключей по следующему процессу:
- Выбирайте столбцы, которые соответствуют вашим типичным фильтрам и шаблонам доступа. Если вы обычно начинаете расследования в области обсервабилити с фильтрации по определенному столбцу, например имени пода, этот столбец будет часто использоваться в
WHERE-выражениях. Отдавайте приоритет включению таких столбцов в ключ по сравнению с теми, которые используются реже. - Отдавайте предпочтение столбцам, которые при фильтрации позволяют исключить большой процент от общего числа строк, тем самым уменьшая объем данных, который необходимо прочитать. Имена сервисов и коды статуса часто являются хорошими кандидатами — во втором случае только если вы фильтруете по значениям, исключающим большинство строк; например, фильтрация по коду 200 в большинстве систем будет соответствовать большинству строк, в то время как ошибки 500 будут соответствовать небольшой подвыборке.
- Предпочитайте столбцы, которые, вероятнее всего, будут сильно коррелировать с другими столбцами в таблице. Это поможет гарантировать, что эти значения также будут храниться последовательно, улучшая сжатие.
- Операции
GROUP BY(агрегации для графиков) иORDER BY(сортировка) для столбцов в ключе упорядочивания могут быть сделаны более эффективными с точки зрения потребления памяти.
После того как вы определили подмножество столбцов для ключа упорядочивания, их необходимо объявить в определенном порядке. Этот порядок может существенно повлиять как на эффективность фильтрации по вторичным столбцам ключа в запросах, так и на коэффициент сжатия для файлов данных таблицы. В общем случае лучше располагать ключи в порядке возрастания кардинальности. Это следует сбалансировать с тем фактом, что фильтрация по столбцам, которые появляются позже в ключе упорядочивания, будет менее эффективной, чем фильтрация по столбцам, которые появляются раньше в кортеже. Сбалансируйте эти особенности и учитывайте ваши шаблоны доступа. И самое главное — тестируйте варианты. Для более глубокого понимания ключей упорядочивания и способов их оптимизации рекомендуется прочитать "Choosing a Primary Key."; для еще более глубокого понимания настройки первичного ключа и внутренних структур данных см. "A practical introduction to primary indexes in ClickHouse."
Изменение первичного ключа
Если вы заранее уверены в шаблонах доступа до начала ингестии данных, просто удалите и заново создайте таблицу для соответствующего типа данных.
В примере ниже показан простой способ создать новую таблицу логов с существующей схемой, но с новым первичным ключом, который включает столбец SeverityText перед ServiceName.
Создать новую таблицу
Обратите внимание, что в приведённом выше примере необходимо указать PRIMARY KEY и ORDER BY.
В ClickStack они почти всегда совпадают.
ORDER BY управляет физической укладкой данных, а PRIMARY KEY определяет разреженный индекс.
В редких случаях очень больших нагрузок они могут отличаться, но большинству пользователей следует держать их согласованными.
Поменять таблицы местами и удалить таблицу
Оператор EXCHANGE используется для атомарной замены имён таблиц. Временную таблицу (теперь это старая таблица по умолчанию) можно удалить.
Однако первичный ключ нельзя изменить у существующей таблицы. Для его изменения требуется создать новую таблицу.
Следующий процесс можно использовать, чтобы старые данные были сохранены и по‑прежнему прозрачно запрашивались (с использованием существующего ключа в HyperDX при необходимости), в то время как новые данные выводятся через новую таблицу, оптимизированную под шаблоны доступа пользователей. Такой подход гарантирует, что конвейеры ингестии не нужно изменять: данные по‑прежнему отправляются в таблицы по умолчанию, а все изменения остаются незаметными для пользователей.
Массовый бэкфилл существующих данных в новую таблицу редко бывает целесообразен. Затраты на вычисления и IO обычно высоки и не окупаются выигрышем в производительности. Вместо этого позвольте старым данным удаляться через TTL, в то время как более новые данные получают выгоду от улучшенного ключа.
Создать новую таблицу
Создайте новую таблицу с требуемым первичным ключом. Обратите внимание на суффикс _23_01_2025 — адаптируйте его к текущей дате, например:
Создать таблицу Merge
Движок Merge (не путать с MergeTree) сам по себе не хранит данные, но позволяет одновременно читать из произвольного числа других таблиц.
currentDatabase() предполагает, что команда выполняется в нужной базе данных. В противном случае укажите имя базы данных явно.
Теперь вы можете выполнять запросы к этой таблице, чтобы убедиться, что она возвращает данные из otel_logs.
Обновить HyperDX для чтения из таблицы Merge
Настройте HyperDX на использование otel_logs_merge как таблицы для источника данных логов.
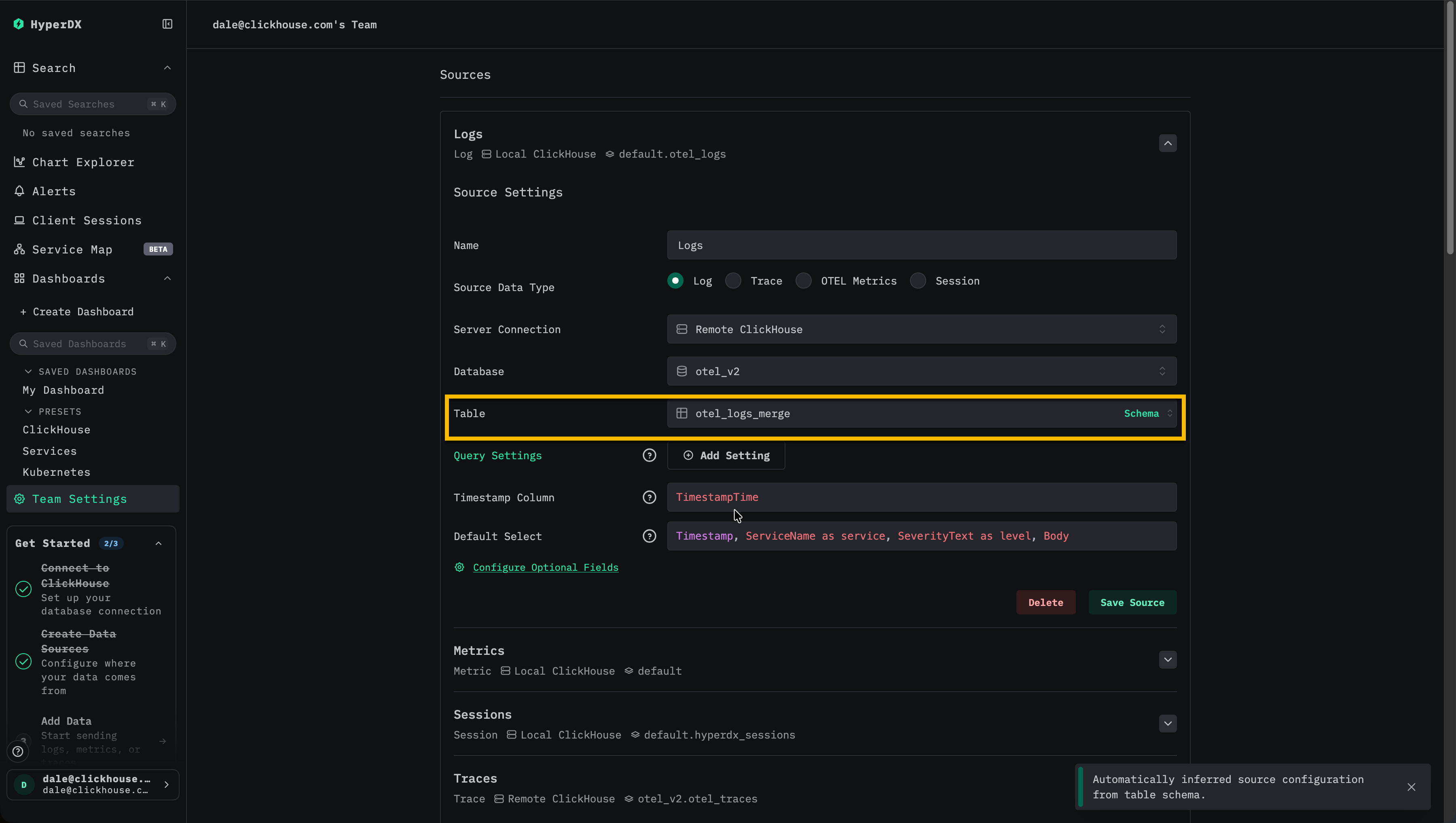
На этом этапе записи продолжают выполняться в otel_logs с исходным первичным ключом, а чтение идёт через таблицу Merge. Для пользователей нет видимых изменений и нет влияния на ингестию.
Поменять таблицы местами
Теперь оператор EXCHANGE используется для атомарной замены имён таблиц otel_logs и otel_logs_23_01_2025.
Записи теперь направляются в новую таблицу otel_logs с обновлённым первичным ключом. Существующие данные остаются в otel_logs_23_01_2025 и по‑прежнему доступны через таблицу Merge. Суффикс указывает дату, когда изменение было применено, и соответствует максимальной метке времени, содержащейся в этой таблице.
Этот процесс позволяет изменять первичный ключ без прерывания ингестии и без видимого влияния на пользователей.
Этот процесс можно адаптировать, если потребуется внести дополнительные изменения в первичные ключи. Например, если через неделю вы решите, что на самом деле SeverityNumber должен быть частью первичного ключа вместо SeverityText. Приведённый ниже процесс можно адаптировать столько раз, сколько потребуется изменений первичного ключа.
Создание новой таблицы
Создайте новую таблицу с требуемым первичным ключом.
В примере ниже 30_01_2025 используется как суффикс для обозначения даты таблицы, например:
Обмен таблицами
Теперь оператор EXCHANGE используется для атомарной перестановки имён таблиц otel_logs и otel_logs_30_01_2025.
Теперь записи направляются в новую таблицу otel_logs с обновлённым первичным ключом. Старые данные остаются в otel_logs_30_01_2025 и доступны через merge-таблицу.
Если заданы политики TTL, что является рекомендуемой практикой, таблицы со старыми первичными ключами, которые больше не принимают записи, будут постепенно опустошаться по мере истечения срока данных. За ними следует наблюдать и периодически очищать их, когда они перестанут содержать данные. В настоящее время этот процесс очистки выполняется вручную.
Оптимизация 4. Использование materialized views
ClickStack может использовать incremental materialized view для ускорения визуализаций, которые зависят от запросов с интенсивной агрегацией, например для вычисления средней длительности запроса по минутам. Эта функция может значительно повысить производительность запросов и обычно наиболее полезна для более крупных развертываний, порядка 10 ТБ в сутки и выше, при этом позволяя масштабироваться до диапазона PB в сутки. Incremental materialized view находятся в статусе Beta и должны использоваться с осторожностью.
Подробнее об использовании этой функции в ClickStack см. в специальном руководстве "ClickStack — materialized views."
Оптимизация 5. Использование PROJECTION
PROJECTION представляют собой финальную, продвинутую оптимизацию, к которой имеет смысл переходить после того, как вы проанализировали materialized columns, skip indexes, primary keys и materialized views. Хотя PROJECTION и materialized view могут выглядеть похожими, в ClickStack они решают разные задачи и оптимальны в разных сценариях.
На практике PROJECTION можно рассматривать как дополнительную, скрытую копию таблицы, которая хранит те же строки в ином физическом порядке. Это даёт PROJECTION собственный первичный индекс, отличный от ключа ORDER BY базовой таблицы, позволяя ClickHouse эффективнее отбрасывать данные для шаблонов доступа, которые не совпадают с исходным порядком.
Materialized view может добиться аналогичного эффекта, явно записывая строки в отдельную целевую таблицу с другим ключом упорядочивания. Ключевое различие в том, что PROJECTION обслуживаются автоматически и прозрачно самим ClickHouse, тогда как materialized view — это отдельные таблицы, которые должны быть явно зарегистрированы и выбраны ClickStack.
Когда запрос направлен к базовой таблице, ClickHouse оценивает базовую схему размещения данных и все доступные PROJECTION, просматривает их первичные индексы и выбирает вариант размещения, который позволит получить корректный результат при чтении наименьшего числа гранул. Это решение автоматически принимает анализатор запросов.
В ClickStack PROJECTION лучше всего подходят для чистого переупорядочивания данных, когда:
- Шаблоны доступа принципиально отличаются от первичного ключа по умолчанию
- Непрактично охватить все сценарии одним ключом упорядочивания
- Вам нужно, чтобы ClickHouse прозрачно выбирал оптимальное физическое размещение данных
Для предагрегации и ускорения метрик ClickStack явно предпочитает явные materialized view, которые дают прикладному уровню полный контроль над выбором и использованием представлений.
Для дополнительной информации см.:
Примеры проекций
Предположим, ваша таблица трейсов оптимизирована под стандартный паттерн доступа ClickStack по умолчанию:
Если у вас также есть основной сценарий работы, в котором фильтрация обычно выполняется по TraceId (или часто осуществляется группировка и фильтрация по нему), вы можете добавить проекцию, которая хранит строки, отсортированные по TraceId и времени:
В примере проекции выше используется подстановочный символ (SELECT *). Хотя выбор подмножества столбцов может снизить накладные расходы на запись, он также ограничивает случаи, когда проекция может быть использована, поскольку только запросы, которые могут быть полностью удовлетворены этими столбцами, будут подходить. В ClickStack это часто ограничивает использование проекции очень узкими сценариями. По этой причине в общем случае рекомендуется использовать подстановочный символ, чтобы максимизировать применимость.
Как и в случае с другими изменениями логической структуры данных, проекция влияет только на вновь записанные части. Чтобы построить её для существующих данных, материализуйте её:
Материализация проекции может занять много времени и потребовать значительных ресурсов. Поскольку данные обсервабилити обычно истекают по TTL, это следует делать только при крайней необходимости. В большинстве случаев достаточно, чтобы проекция применялась только к вновь поступающим данным, оптимизируя таким образом наиболее часто запрашиваемые диапазоны времени, например последние 24 часа.
ClickHouse может выбрать проекцию автоматически, если оценивает, что она просканирует меньше гранул, чем базовая структура. Проекции наиболее надежно и эффективно работают, когда они представляют собой простое переупорядочивание полного набора строк (SELECT *), а фильтры запроса хорошо согласуются с ORDER BY проекции.
Запросы, которые фильтруют по TraceId (особенно по равенству) и включают диапазон времени, выиграют от приведённой выше проекции. Например:
Запросы, которые не ограничивают TraceId или в основном фильтруют по другим измерениям, не находящимся в начале ключа сортировки проекции, как правило, не дают заметного выигрыша (и вместо этого могут выполняться через базовый layout).
Projections также могут хранить агрегированные данные (аналогично materialized views). В ClickStack агрегаты на основе проекций в целом не рекомендуются, так как выбор зависит от анализатора ClickHouse, а использование сложнее контролировать и интерпретировать. Вместо этого предпочитайте явные materialized views, которые ClickStack может регистрировать и выбирать целенаправленно на уровне приложения.
На практике проекции лучше всего подходят для сценариев, где вы часто переходите от более широкого поиска к детализированному анализу конкретного trace (например, выбор всех spans для конкретного TraceId).
Затраты и рекомендации
- Накладные расходы при вставке:
SELECT *-проекция с иным ключом сортировки по сути означает, что данные записываются дважды, что увеличивает объём операций записи (write I/O) и может потребовать дополнительную пропускную способность CPU и дисковой подсистемы для поддержания скорости ингестии. - Используйте умеренно: Проекции лучше всего оставлять для действительно разных шаблонов доступа, когда альтернативный физический порядок сортировки обеспечивает значимое отсечение объёма данных для большой доли запросов, например, когда две команды выполняют запросы к одному и тому же набору данных принципиально разными способами.
- Проверяйте с помощью бенчмарков: Как и для любой настройки, сравните фактическую задержку запросов и использование ресурсов до и после добавления и материализации проекции.
Для более детального ознакомления см.:
Облегчённые проекции с _part_offset
_part_offset-based облегчённые проекции не рекомендуются для рабочих нагрузок ClickStack. Хотя они уменьшают объём хранилища и количество операций записи (I/O), они могут приводить к большему количеству случайных операций доступа во время выполнения запроса, а их поведение в продакшене при масштабе обсервабилити всё ещё оценивается. Эта рекомендация может измениться по мере развития функциональности и накопления эксплуатационных данных.
Более новые версии ClickHouse также поддерживают более лёгкие проекции, которые хранят только ключ сортировки проекции плюс указатель _part_offset в базовую таблицу, вместо дублирования полных строк. Это может существенно сократить накладные расходы на хранение, а недавние улучшения позволяют выполнять отсечение (pruning) на уровне гранулы, в результате чего они ведут себя более похоже на настоящие вторичные индексы. См.:
Alternatives
Если вам нужно несколько ключей сортировки, проекции — не единственный вариант. В зависимости от эксплуатационных ограничений и того, как вы хотите, чтобы ClickStack маршрутизировал запросы, рассмотрите:
- Настройку вашего OpenTelemetry collector на запись в две таблицы с разными ключами
ORDER BYи создание отдельных источников ClickStack для каждой таблицы. - Создание materialized view как конвейера копирования, то есть присоединение materialized view к основной таблице, которая выбирает «сырые» строки во вторичную таблицу с другим ключом сортировки (паттерн денормализации или маршрутизации). Создайте источник для этой целевой таблицы. Примеры можно найти здесь.
